For each answer you get right, we donate 10 grains of rice through the World Food programme to help end hunger
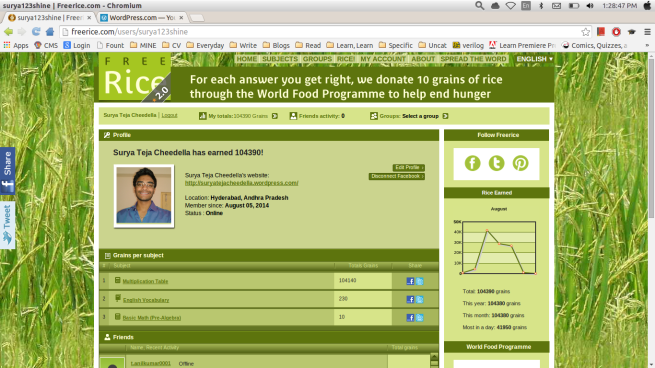
That’s what guys at freerice.com say. So, I answered 10,439 questions correctly, ending up donating 104,390 rice grains. 😀 As I mentioned in one of my previous posts, I am working on OCR (Optical Character Recognition) to win a bet with my friend. I have completed building an OCR system and donated 104,390 rice grains on this website freerice.com in a single day under United Nations world food program. As I said, I built this just to win a bet. This whole post is one down and dirty way to build a working OCR system. I know this isn’t efficient way to do this even. (that’s the reason for MARK I 😛 ) Here’s a screenshot of my score (aka rice grains donated) on that site-
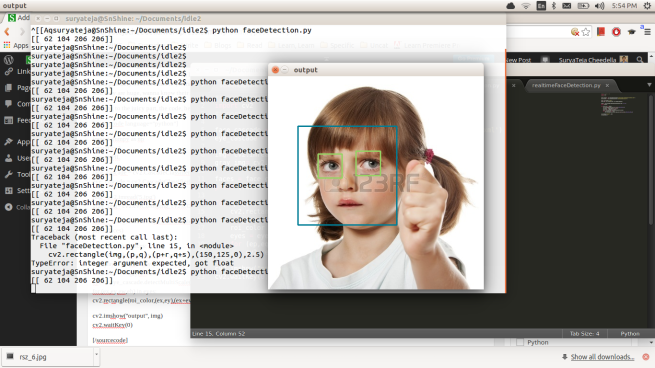
And a screenshot while the code is running:

So, lets dive into the juicy part, the code- The whole process is divided into small points.
- Take a screenshot while the required page, freerice.com in our case, is opened, crop it to get the area we are interested in to recognize characters i.e where the multiplication tables are. (Here in this project it is going to answer only multiplication type questions) Save the cropped image.
- Analyse that image with Tesseract OCR to get a text file of recognized characters as output. (eventually saving it as a txt file next to our main program, I mean the folder)
- Analyze that txt file and get the recognized information. (We are dealing with integers, so, convert a string txt file into integers)
- After analysing the information in txt file, we get to know the question (7×4 or something like that) and check for answer in options.
- If the answer matches any of the options, move the mouse onto specific region. (works for me. It basically click on that pixel value, where that option is on screen, which I found by trail and error on my laptop)
- If tesseract couldn’t find the correct answer, (answer we got by solving the first line (7×4 for example) and answer by analysing the options) it randomly clicks on any of the four options just not to break the loop. (LOOP? where’s that? See next point)
- Embed everything from 1 to 6 points in a loop so, it does its work while you are sleeping. 😀
I have briefly commented what’s each line is contributing to the code, making it as a whole.
#Import required libraries. We need to download some, if you don't have tham.
import cv2
import os
import pyscreenshot as ImageGrab
import numpy as np
import time
from pymouse import PyMouse
import random
#defining a function rand.
def rand():
m = PyMouse()
#find a random int and put it into 'do'
do= random.randint(1,4)
#basic if, elif loop
if do == 1:
#clicking at point (395, 429). Here 1 implies a left-click
m.click(395, 429, 1)
elif do== 2:
m.click(395, 466, 1)
elif do == 3:
m.click(395, 505, 1)
else:
m.click(395, 544, 1)
m.move(50,50)
print("Rand")
#wait for 1 sec, giving time to browser to refresh
time.sleep(1)
trails= 0
#two forloops because, I am waiting for 5 secs after every 10 calculations just to make the system stable
for guns in range (0,1000):
for buns in range(0,10):
#Using try,catch to avoid any errors
try:
img= ImageGrab.grab() #taking a screenshot
img.save('output.png')
pic= cv2.imread('output.png')
pic2= pic[360:570, 380:470] #cropping the pic, works in my case
cv2.imwrite('output.png', pic2)
u= 'convert output.png -resize 700 output.png'
os.system(u) #writing to terminal (re-sizing the pic)
s= 'tesseract output.png output'
os.system(s) #writing to terminal (running Tesseract)
f= open('output.txt', 'r')
string= f.read().replace('\n', ' ')
string= string.replace(' ', ' ')
string= string.replace(' ', ' ')
first= string[:string.find('x')] #finding first integer
second= string[string.find('x')+1:string.find(' ')] #finding second integer
pro= int(first)*int(second)
print(pro)
print(string)
m= PyMouse()
string= string[string.find(' ')+1:]
a= int(string[:string.find(' ')])
#print(a)
#checking if product is equal to any of answers and clicking on that particular option
if pro == a:
m.click(395, 429, 1)
m.move(50,50) #move cursor to any random point which is not in our area of interest, avoiding tesseract to think it as some character
print("Pass")
time.sleep(1)
else:
string= string[string.find(' ')+1:]
b= int(string[:string.find(' ')])
#print(b)
if pro == b:
m.click(395, 466, 1)
m.move(50,50)
print("Pass")
time.sleep(1)
else:
string= string[string.find(' ')+1:]
c= int(string[:string.find(' ')])
#print(c)
if pro == c:
m.click(395, 505, 1)
m.move(50,50)
print("Pass")
time.sleep(1)
else:
d= int(string[string.find(' ')+1:])
#print(d)
if pro == d:
m.click(395, 544, 1)
m.move(50,50)
print("Pass")
time.sleep(1)
else:
rand() #tesseract can't detect 100% accurately. So, tick any option randomly in case it didn't find correct answer
#print("haha")
except (ValueError, NameError, TypeError):
rand() #tick randomly in case of any errors
trails+= 10
print("Total= " + str(trails))
time.sleep(5) #waiting for 5secs after every 10 loops to make my system stable.
I’ll be back soon with MARK II of OCR system and next time I’ll not be using TesseractOCR. (Target accuracy- 90% (just a thought, though)) If you have any questions or some feedback, please feel free to add comments. I’d be happy to get some feedback from you. So, happy donating. Any time
-SuryaTeja Cheedella